 文武科技柜
文武科技柜 2024年推荐15个AI大模型评测基准和排行榜平台

文章目录

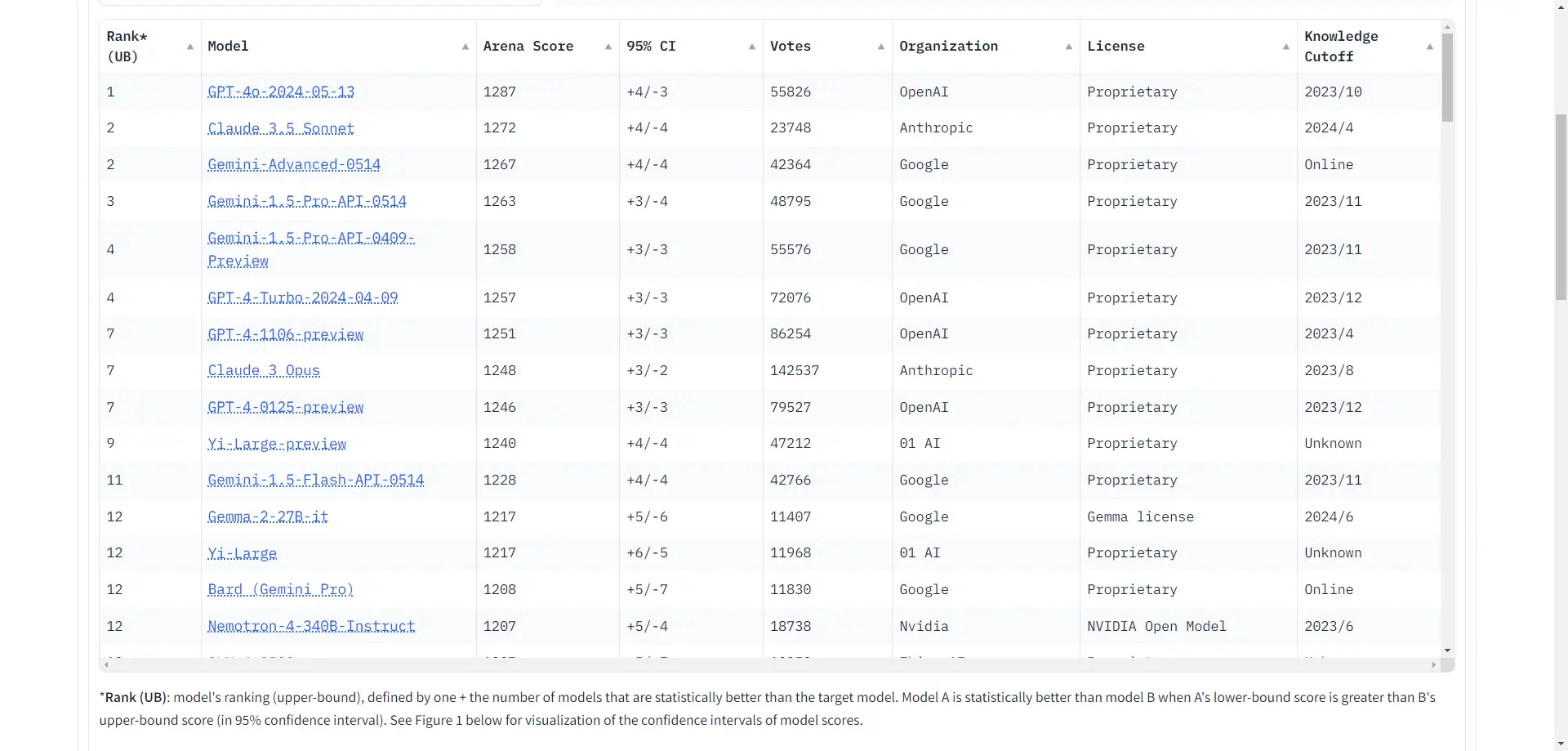
LMSYS Chatbot Arena👍
Chatbot Arena(备) 是由伯克利大学主导团队LMSYS Org发布的一个基准平台,用于大型语言模型(LLM)的对抗评测。该平台采用匿名和随机的方式,让不同的大型模型进行对抗评测,并通过众包方式收集用户反馈和评分。Chatbot Arena使用Elo评分系统,这是一种在国际象棋等竞技游戏中广泛使用的评分方法,以确保评测的客观性和公正性。
Chatbot Arena不仅是一个评测平台,还提供了一个开放的社区驱动的环境,用户可以通过投票来评估不同模型的表现。此外,该平台还支持多模态评测,允许用户与视觉-语言模型进行交互并进行比较。总的来说,Chatbot Arena已成为全球业界公认的基准标杆,广泛应用于大型语言模型的开发和评估。
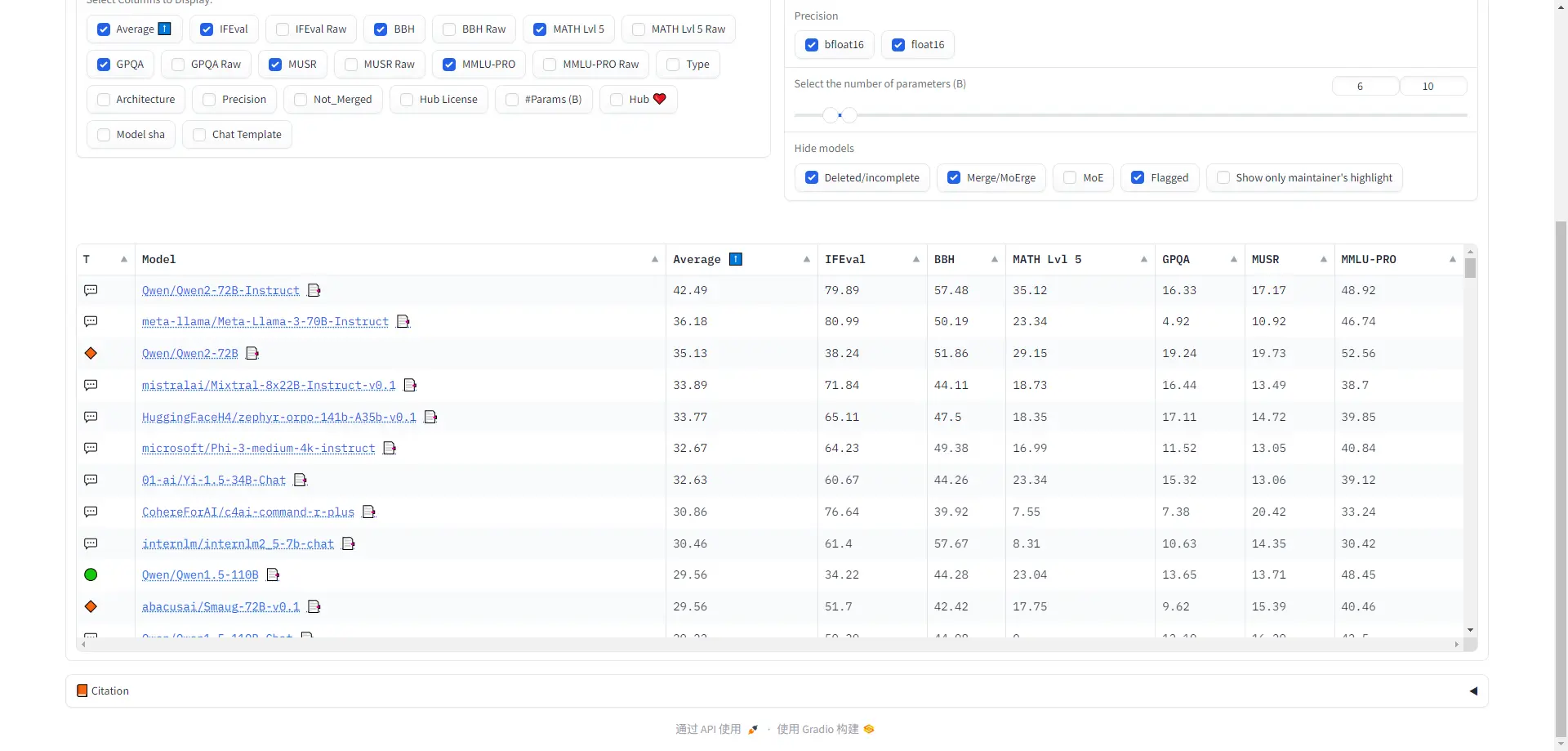
Open LLM Leaderboard
Open LLM Leaderboard 是由Hugging Face推出的一个平台,用于追踪和排名开源大型语言模型(LLMs)和聊天机器人。该排行榜基于多个基准测试,包括ARC、HellaSwag和MMLU等,并允许用户根据模型类型、精度、架构等选项进行过滤。此外,Open LLM Leaderboard还引入了开放式问题评估方法,以消除传统选择题中的固有偏见和随机猜测。
该排行榜不仅提供了一个清晰、客观的模型性能评估标准,还通过严格的基准测试和公平的评分系统,反映了不同LLMs的真实能力。用户可以在Hugging Face平台上访问和使用这个排行榜,以便更好地了解当前大模型的发展状况并进行优化。
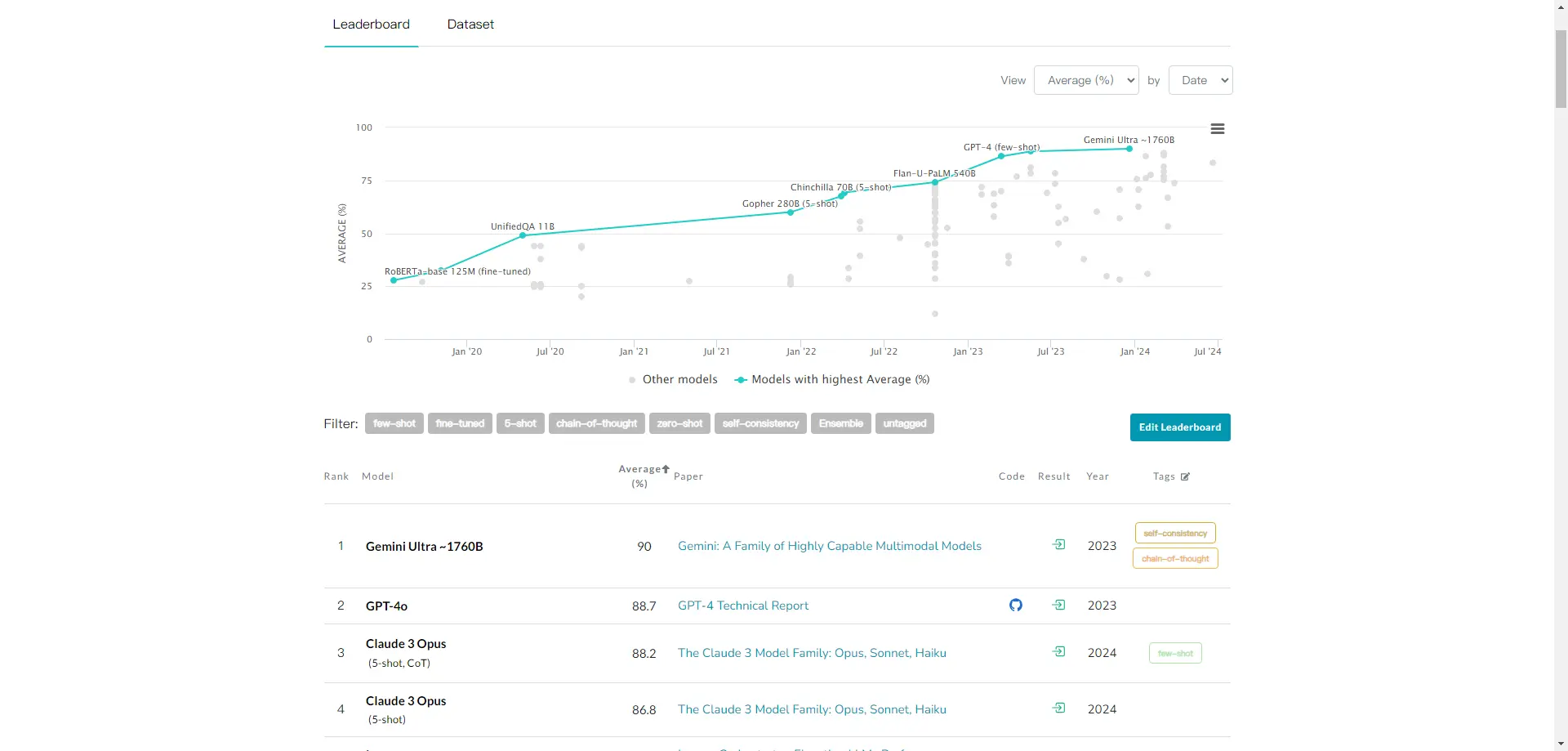
MMLU Benchmark
MMLU Benchmark (Massive Multitask Language Understanding)是一个用于评估多任务语言理解模型性能的基准测试。它通过提供多个语言理解任务和模型对比,适用于各种需要进行多任务语言理解的场景。该基准测试覆盖了57个主题,包括STEM、人文学科、社会科学等领域。MMLU Benchmark旨在衡量模型在零样本(zero-shot)和少样本(few-shot)设置下的多任务能力,并通过统一的评估框架来全面评估语言模型的整体性能。
此外,MMLU Benchmark包含一个包含15908个问题的数据集,分为几组开发集、验证集和测试集,以测量文本模型在不同任务中的多任务准确率。这个基准测试不仅用于评估模型的知识水平,还强调模型在理解和生成语言方面的能力,涵盖机器翻译、文本摘要和情感分析等多种任务。
SuperCLUE
SuperCLUE(中文通用大模型综合性测评基准),是针对中文可用的通用大模型的一个测评基准。
它主要要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况。包括但不限于:这些模型哪些相对效果情况、相较于国际上的代表性模型做到了什么程度、 这些模型与人类的效果对比如何?它尝试在一系列国内外代表性的模型上使用多个维度能力进行测试。SuperCLUE,是中文语言理解测评基准(CLUE)在通用人工智能时代的进一步发展。
目前包括三大基准:OPEN多轮开放式基准、OPT三大能力客观题基准、琅琊榜匿名对战基准。
H2O LLM Eval
H2O LLM Eval 是一个用于评估大型语言模型(LLM)性能的系统。它属于H2O Eval Studio的一部分,该工作室是一个模块化且可扩展的平台,旨在系统地评估检索增强生成(RAG)和大型语言模型的应用性能、可靠性、安全性、公平性和有效性。H2O LLM Eval使用ELO评分方法来计算基于A/B测试结果的ELO分数。此外,H2O LLM Eval还提供了生成评估结果、热力图排行榜以及模型和提示的元数据等功能。
PubMedQA
PubMedQA 是一个生物医学研究问答(QA)数据集,旨在通过相应的摘要以是/否/可能的方式回答研究问题。该数据集从PubMed摘要中收集而来,包含了1K个专家标注的问题、61.2K个未标注的问题和211.3K个人工生成的QA实例。PubMedQA的任务是使用这些摘要来回答研究问题,例如术前他汀类药物是否能减少冠状动脉旁路移植术后的心房颤动。
此外,PubMedQA是第一个需要对生物医学研究文本进行推理,特别是其定量内容的问答数据集。该数据集由匹兹堡大学和卡内基梅隆大学等机构提出,并在2019年的会议论文集中发表。
FlagEval
FlagEval(天秤)大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用 AI 方法实现对主观评测的辅助,大幅提升评测的效率和客观性。FlagEval(天秤)创新构建了“能力 - 任务 - 指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果。目前已推出语言大模型评测、多语言文图大模型评测及文图生成评测等工具,并对广泛的语言基础模型、跨模态基础模型实现了评测。后续将全面覆盖基础模型、预训练算法、微调 / 压缩算法等三大评测对象,包括自然语言处理(NLP)、计算机视觉(CV)、音频须(Audio)及多模态(Multimodal)等四大评测场景和丰富的下游任务。
FlagEval 是智源 FlagOpen 大模型开源技术体系的重要组成部分。FlagOpen 旨在打造全面支撑大模型技术发展的开源算法体系和一站式基础软件平台,支持协同创新和开放竞争,共建共享大模型时代的“Linux”开源开放生态。
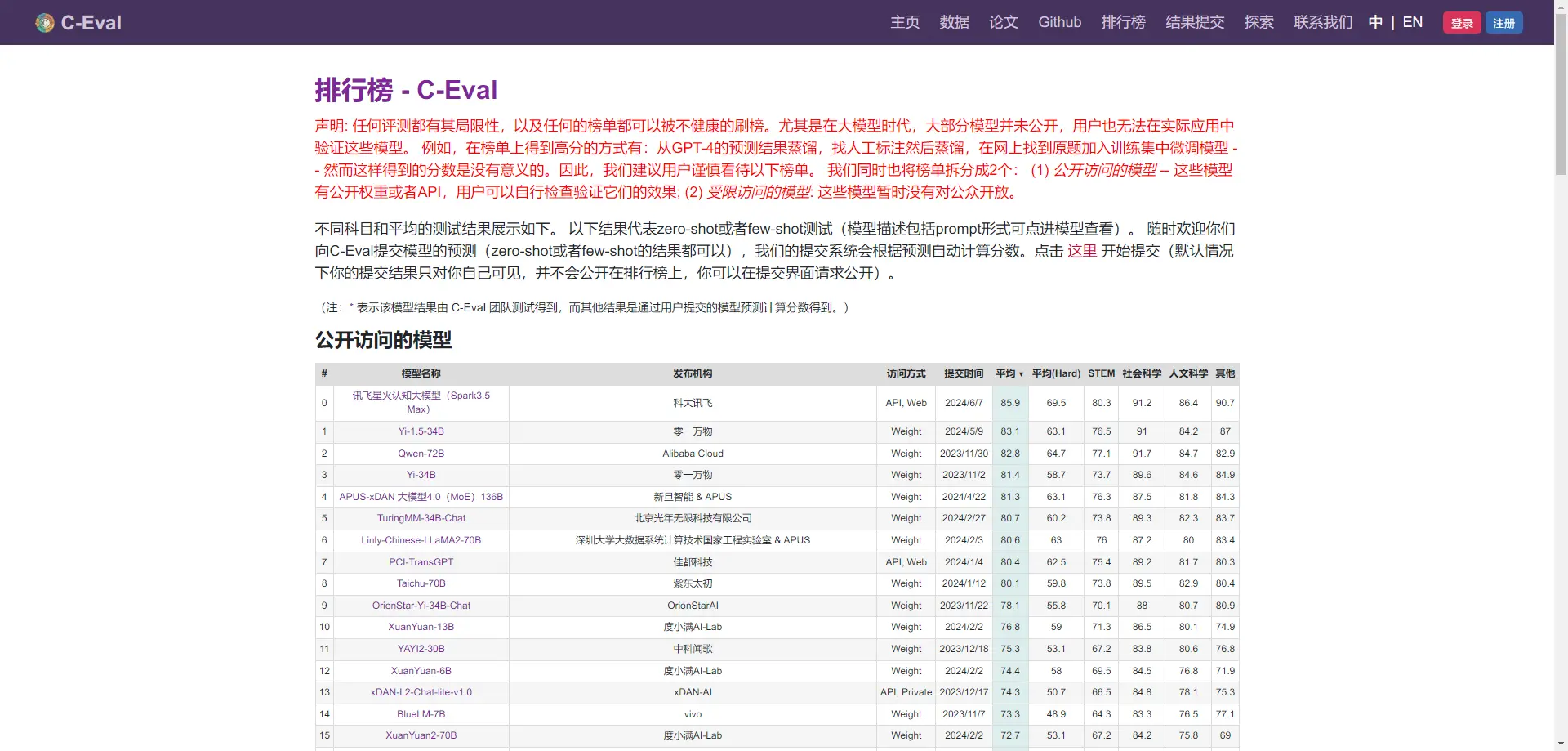
C-Eval
C-Eval 是一个全面的中文基础模型评估套件,由上海交通大学、清华大学和爱丁堡大学的研究人员在2023年5月份联合推出。它旨在评估大规模语言模型(LLM)的知识和推理能力,包含13948个多项选择题,涵盖了52个不同的学科和四个难度级别:初中、高中、大学和专业。
C-Eval的核心特点在于其多层次多学科的设计,能够全面评估大模型的语言理解、生成能力和逻辑推理等多维度性能。此外,C-Eval不仅用于评测模型的性能,还旨在辅助模型开发,帮助开发者科学地使用该评测工具进行模型迭代。
C-Eval是一个权威的中文AI大模型评测数据集,适用于考察大模型的知识和推理能力,并且在全球范围内具有较高的影响力。
CMMLU
CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
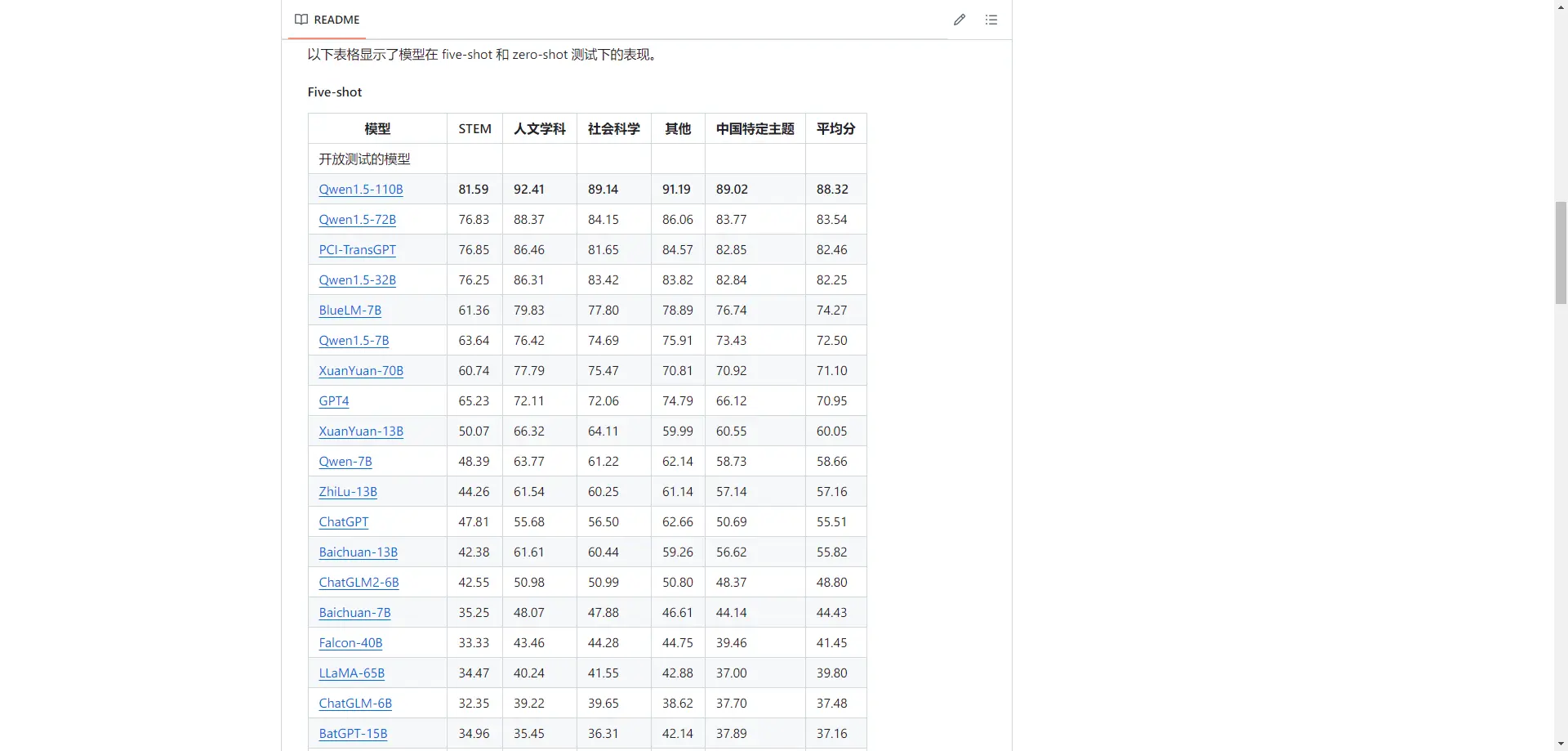
OpenCompass
OpenCompass 是一个由上海人工智能实验室发布的开源大模型评测平台,旨在提供公平、公开和可复现的大模型评测方案。它构建了一个包含学科、语言、知识、理解、推理五大维度的通用能力评测体系,能够全面评估大模型的能力。此外,OpenCompass还支持多模态模型的评测,并定期公布评测结果。
OpenCompass不仅支持多种先进的自然语言处理模型,如InternLM2、GPT-4、LLaMa2、Qwen以及GLM和Claude等,还整合了丰富的数据集和问题库,提供了70多个数据集和约40万个问题的模型评估方案。它的评测系统设计灵活,用户可以根据需要增加新模型或数据集,甚至自定义更高级的任务分割策略。
OpenCompass已经成为目前权威的大型模型评估平台,广泛应用于大语言模型和多模态模型的评测中。
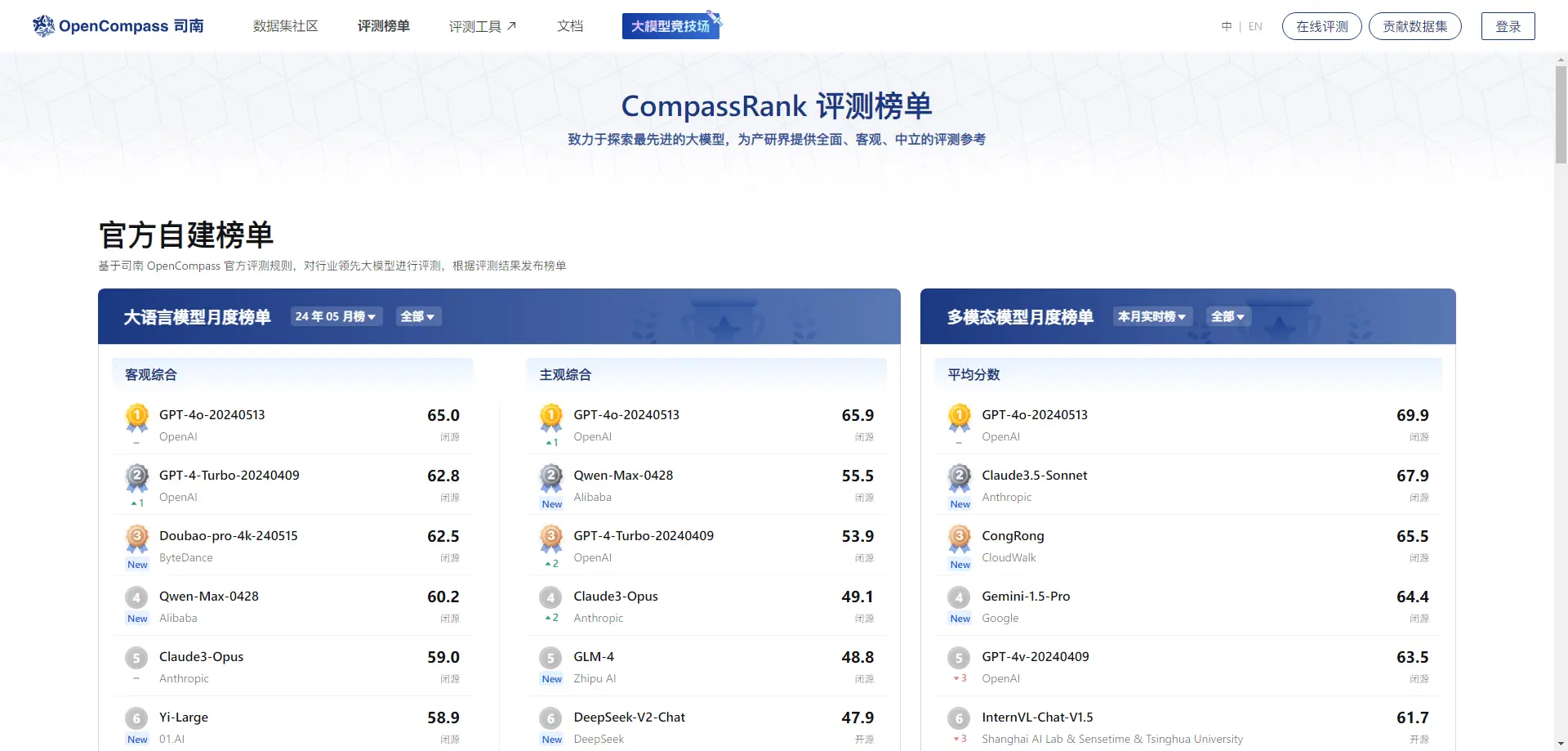
chinese-llm-benchmark
- 目前已囊括88个大模型,覆盖chatgpt、gpt4、谷歌bard、百度文心一言、阿里通义千问、讯飞星火、商汤senseChat、微软new-bing、minimax等商用模型, 以及百川、qwen2、chatglm、openbuddy、AquilaChat、vicuna、书生internLM2、llama3等开源大模型。
- 模型来源涉及国内外大厂、大模型创业公司、高校研究机构。
- 支持多维度能力评测,包括分类能力、信息抽取能力、阅读理解能力、数据分析能力、中文编码效率、中文指令遵从。
- 不仅提供能力评分排行榜,也提供所有模型的原始输出结果!
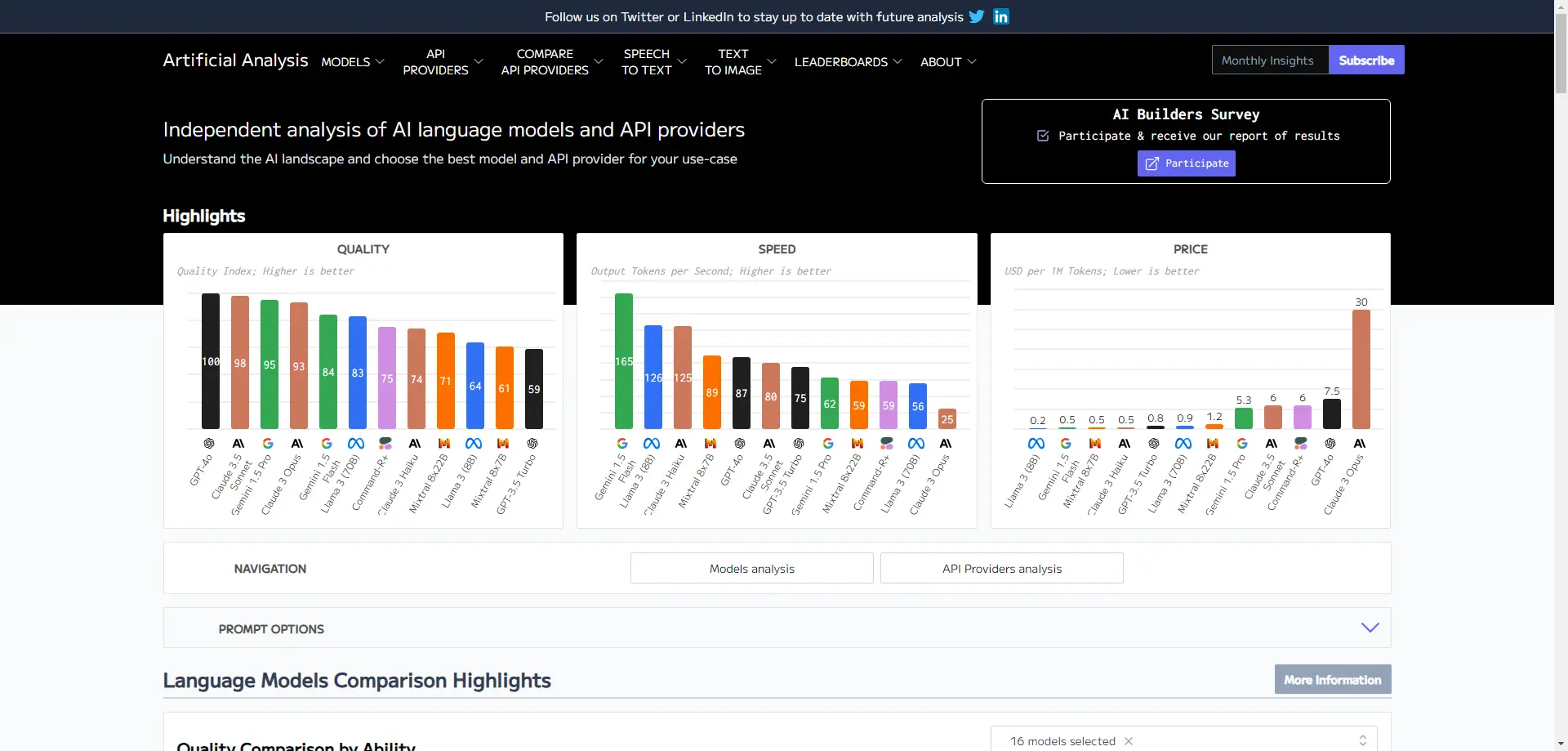
Artificial Analysis
Artificial Analysis 是一个专注于AI语言模型和API提供商的独立分析平台。它提供详细的性能评估,帮助用户理解AI领域的格局,并为他们的具体用例选择最佳的模型和API提供商。该平台通过质量指数、吞吐量和价格等多个维度对不同的AI模型进行比较,使用户能够做出更明智的选择。
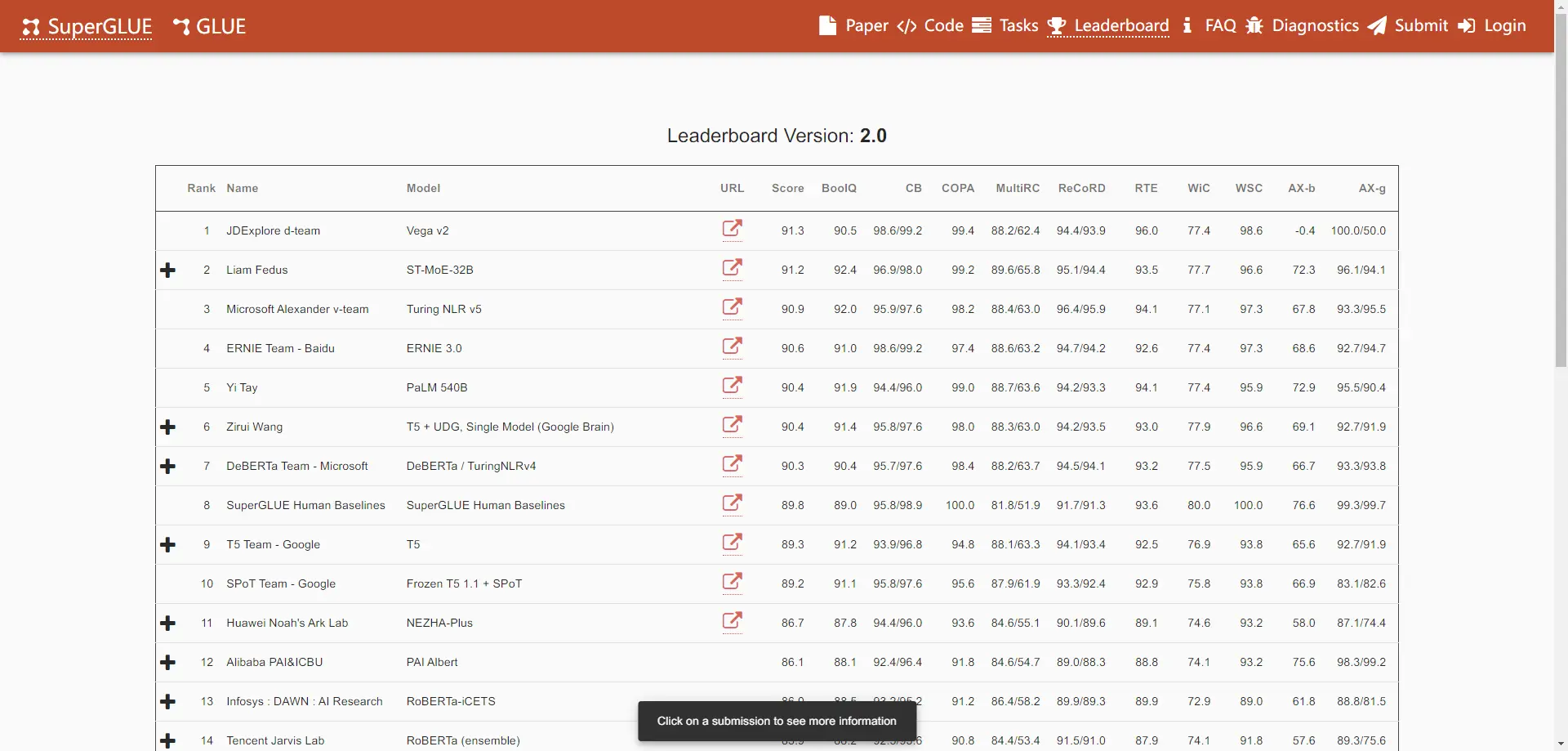
SuperGLUE
SuperGLUE 是一个用于评估自然语言处理(NLP)模型性能的基准任务集合。它包含了多个任务,每个任务都有不同的输入和输出要求。SuperGLUE的目标是提供一个更全面和挑战性的测试集,以便更好地评估NLP模型的能力。该基准数据集旨在对语言理解进行比GLUE更严格的测试,提供一个简单的、难以玩游戏的方法来衡量英语通用语言理解技术的进步。
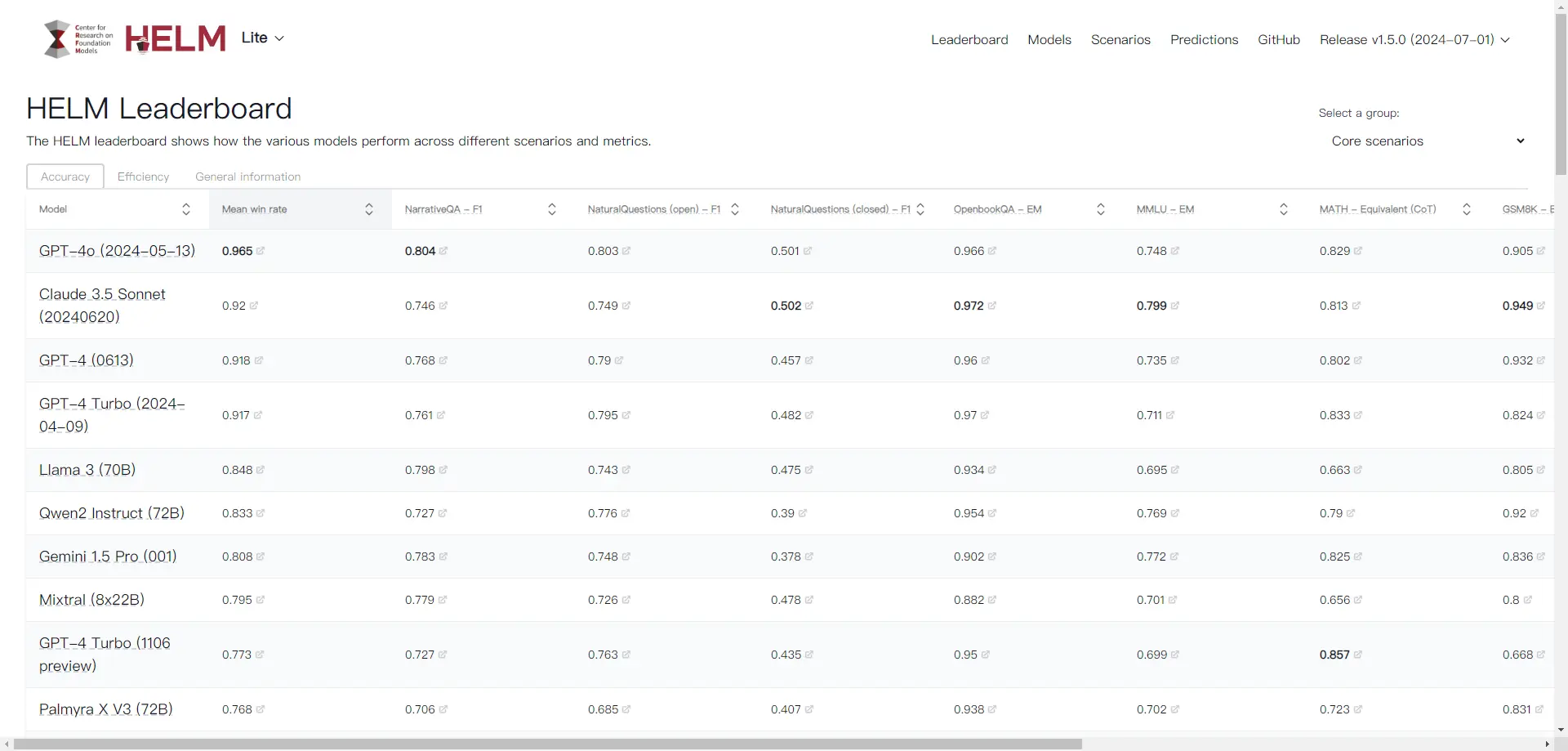
HELM
Holistic Evaluation of Language Models (HELM) 是由斯坦福大学推出的一个综合评估语言模型的平台,旨在提高语言模型的透明度和全面性。HELM 通过多维度的评估方法,涵盖多个不同的自然语言处理任务,如文本分类、命名实体识别和关系抽取等。该评测体系包括场景、适配和指标三个模块,能够为大型语言模型提供全面的质量评估。
HELM 的主要目标是通过标准化评估方法和广泛的覆盖范围,帮助用户了解和选择适合自己需求的语言模型。它采用多指标测量方法,并实现标准化,从而对众多语言模型进行评估。此外,HELM 还提供了一个统一的 API,使得研究人员可以方便地访问和测试不同的语言模型。
总之,HELM 是一个先进的语言模型评估框架,通过多维度的评估方法和广泛的覆盖范围,全面了解和提升语言模型的性能和透明度。
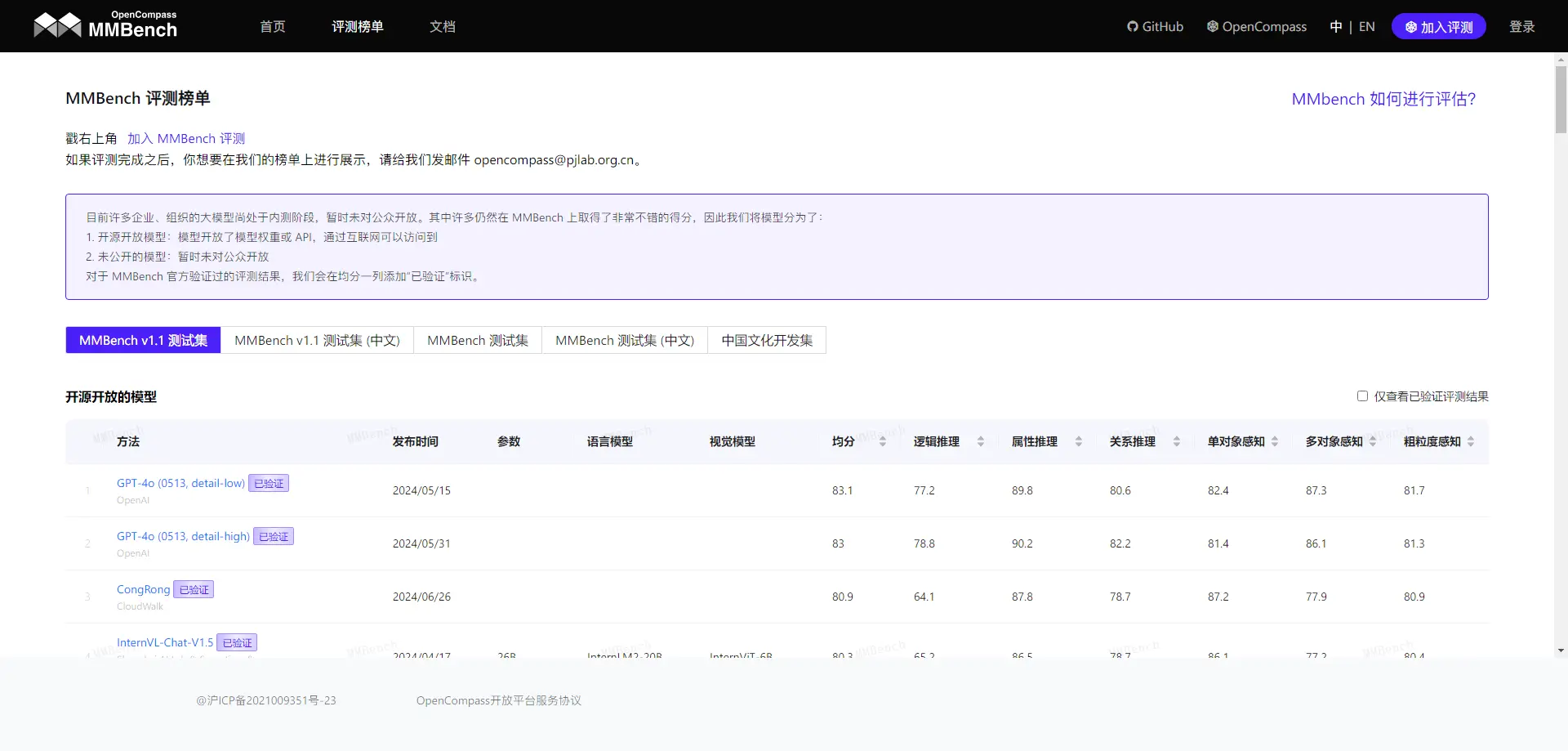
MMBench
MMBench 是一个多模态基准测试平台,旨在评估和比较不同多模态模型在语言理解、视觉理解和联合理解任务上的性能。它由上海人工智能实验室、南洋理工大学、中国香港中文大学、新加坡国立大学和浙江大学的研究人员共同开发,提供了一个综合评估流程,从感知到认知能力逐级细分评估,覆盖了20项细粒度能力。
MMBench的评测数据集包含约3000道单项选择题,这些题目从互联网公开信息与权威基准数据集中精心挑选而来,涵盖了目标检测、文字识别、动作识别、图像理解、关系推理等多个维度。此外,MMBench还引入了一种新颖的CircularEval策略,并结合了多种评估指标和基准数据集,帮助用户全面了解和比较不同模型的性能。
MMBench不仅适用于多模态模型的研究和开发领域,还为研究人员提供了丰富的评估工具和数据资源,以促进多模态大模型的发展。


共有 0 条评论